![]()
Pump Pros Know- Reliability
What do Pump Pros Know and why do they know it? This series of articles highlight the brilliance of those who work with pumps.

The Importance of Pump Reliability
We usually think of reliability as how long a machine operates without breaking down. If a machine repeatedly breaks down, we consider it unreliable. But a component or system doesn’t have to break down completely to be unreliable. It would also lack reliability if it continued to operate, but frequently failed to provide the stated performance or utility.
Experts who deal with the reliability of pumping systems and components often review the number of failures of a population of equipment over a given time as a starting point in understanding and benchmarking reliability. This has led to the use of the common abbreviation MTBF (mean time between failure) and its cousin MTBR (mean time between repair), and their application in reliability assessment of industrial pumping systems has been evolving for decades. MTBF measures the average time the pump operates between breakdowns (failures), while MTBR includes downtime for failures, planned maintenance or any other categorization of repair events.
On balance the second largest component of a pump’s life cycle cost (Figure 1) is maintenance accounting for 25%, only behind energy consumption. Therefore, focus is given to capturing reliability data, developing databases and software to calculate these and a wide array of reliability reports. Increasing MTBR became the primary metric along with the associated life cycle cost savings to justify a greater focus on reliability improvements in pumping systems.
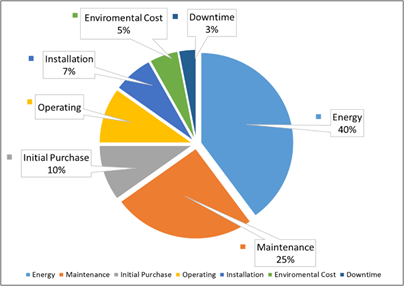
Figure 1 – Typical Pump Life Cycle Cost Components
Reliability Centered Maintenance
Reliability-centered maintenance (RCM) is a system approach to preserve the health and effectiveness of pumping systems. Selecting a component for a certain function should include a theoretical life designed to exceed the practical life experienced in most installations. Ideally, equipment overhaul would occur just before the component reaches the end of its useful life. However, most components fail before this point. These premature failures require reactive, unplanned maintenance, which is often followed by analyzing the cause of the failure.
Traditionally, RCM divides failures into three categories: early (infant mortality), random (process upsets), and wear-out (useful life), See Figure 2. Reliability studies show that most failures are random. After start-up, equipment will show signs of deterioration over time. This could be lower output, greater noise, higher temperature, or similar conditions. RCM seeks to detect the deterioration point early in the life of the component. From this point until the equipment fails is known as the potential failure (PF)interval. Observations made during the PF interval allow for in-service adjustment to asset operation and planning, and staging of the maintenance event.
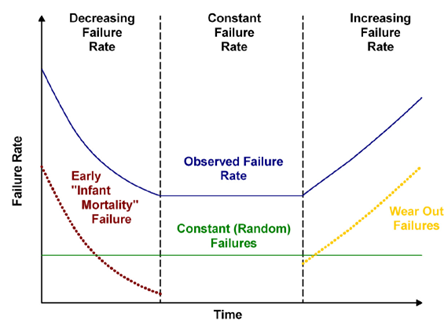
Figure 2 – RCM general bathtub curve
Planned versus Unplanned Maintenance
Reducing the frequency of unplanned maintenance events requires tracking and measuring planned and unplanned equipment shutdowns. Reducing and eliminating these shutdowns requires a feedback loop where historical performance and failure causes can be categorized, which often starts with tracking MTBR.
Most premature failures in rotating equipment result from incorrect material specification, inadequate maintenance, improper operational process procedures, or a combination of these. Although most equipment failures are considered random, they can occur within any of the three RCM failure categories.
When recording the repairs it is important to include a probable cause of each failure and ideally gather condition data prior to the failure, which can help pinpoint future items to monitor that could help identify the onset of failure.
The potential failure (PF) curve, Figure 3, illustrates the general behavior of equipment relative to a measured condition, time, and failure. After start-up the equipment will show signs of measurable deterioration. The measurable item could be many different system variables or specific items on the pumping equipment such as vibration or bearing temperature. RCM seeks to detect the deterioration point early in the life of the asset. From this point to occurrence of failure, the range of time is known as the PF interval. Observations made during the PF interval allow for in-service adjustment to asset operation, and planning and staging of the maintenance event. Refer to ANSI/HI 9.6.5 and ANSI/HI 9.6.9 for guidelines on the monitoring indicator and control limits for rotodynamic and rotary pumps.
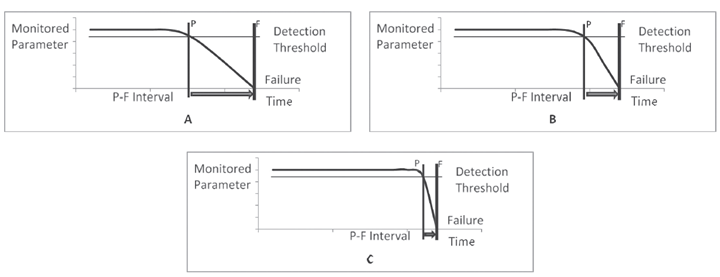
Figure 3 –Potential Failure Curve
Should you monitor the condition of pumps to determine the PF Interval?
RCM systems define the criticality of assets. Criticality may be a function of safety, production availability, repair cost, or other factors. RCM may incorporate a strategy allowing noncritical assets to run-to-failure. In contrast, critical assets carry a greater need for continuous monitoring.
Condition monitoring of pumps works hand-in-hand with efforts to improve the reliability of pumping systems. Condition monitoring entails monitoring a pump’s vital operating characteristics on a regular basis to determine the machine’s health and provide an early indication of potential problems. Although condition monitoring will not improve the MTBR on its own, it provides data that may allow the pump to be shut down prior to a catastrophic failure, and at a more convenient time during the PF interval, thereby avoiding a production stoppage. This gives maintenance personnel the time to plan the repair, assemble the proper tools and other resources, and properly execute the repair during scheduled downtime. This is important because it limits fire drills, lost production due to unexpected failures and emergency or temporary repairs to keep production running.
Being able to monitor pump, motor, and process variables such as temperature, vibration, power, pressure, flow, level, etc. is essential for detecting system performance and equipment deterioration or failure.
The choice of parameters to monitor will depend on safety, cost of failure, the cost of instrumentation, and industry regulations and standards. Overall, it makes sense to have a formal reliability measurement and improvement program to improve the safety and reliability of your plant.
Check out the other Pump Pros Know!